


Reproducibility is the foundational principle of the scientific method. If an experiment cannot be repeated, it is assumed to be faulty. DKube, an end-to-end Kubeflow-based MLOps platform, offers complete reproducibility into an integrated workflow. Without the ability to trace and repeat your work, it is not science
Why Is Reproducibility Important?

The ability to track and reproduce your data is critical throughout the ML/DL process.
Table to be inserted
Reproducibility has some important aspects:
- All pertinent information needs to be captured so that the full history is provided
- The history should be done automatically, without needing to instrument the code or take manual actions
- It should be quick and simple to take the run and do a new version with variations for comparison
- It should be straightforward to provide automation, so that input changes can be used for repetition
- It should be integrated with the rest of your workflow
ML/DL Workflow
The overall workflow for developing a model can be summarized by the following general phases:

These phases can be combined in different ways depending upon the size and formality of the organization, but the basic approach is similar for most data science projects.
The ML Engineer phase is where reproducibility is the most valuable. The basic training code has been developed, and the entire environment needs to be optimized to address inference on real data.
- Different datasets are used to understand how the training is impacted. The datasets would normally be larger for this phase than for the basic development phase and would better represent the final inference data. It is far too easy to overfit or underfit based on a smaller dataset than is feasible during initial development.
- Hyperparameter choices will make a significant difference to the outcome, and given the potentially explosive number of possibilities, traceability becomes a primary goal.
With all those variables in play, the number of training runs and models can become large, and it is somewhere between challenging and impossible to analyze what option caused which outcome without some assistance from the platform.
Reproducibility with DKube™
DKube, an end-to-end MLOps platform, provides all this assistance automatically, and it is fully integrated into your workflow. DKube is based on Kubeflow, a standards-based platform that brings together best-in-class frameworks and systems. DKube extends this baseline to provide an integrated & supported DL/ML platform.

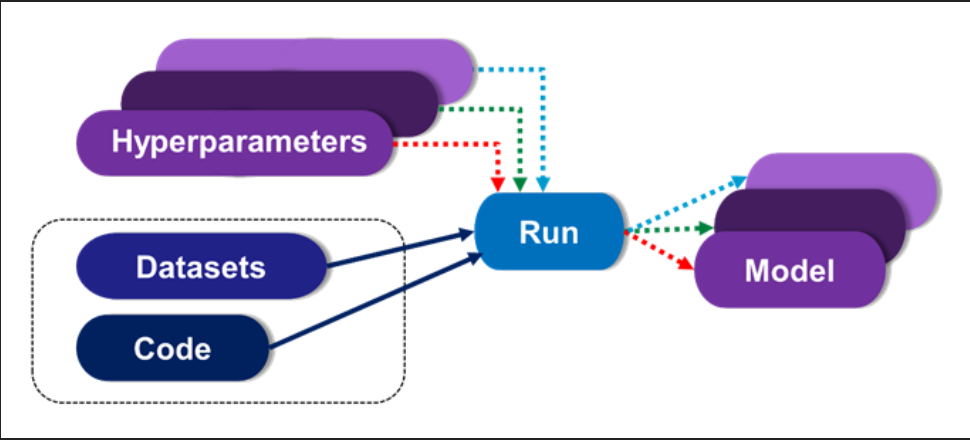
The first step in bringing order to this chaos is to use versioning when creating new models. When a training run is executed, the output can be either a new version of an existing model, or it can be an entirely new model.
Versioning is a way to combine models that have some common heritage, but with a limited number of differences in the input. For example, you might want to see how different hyperparameters impact your selected metrics. This can be used to compare the metrics to determine the best fit.
In this example based on DKube, the model lineage is shown after a training run. The input code and datasets are provided, along with any additional hyperparameters, and the training run is identified.

Navigating to the associated code, dataset, or run is accomplished by selecting it directly from the lineage box. From this screen, you can:
- Reproduce the model using the same set of inputs to ensure repeatability
- Create a new training run with different inputs by cloning the run
- Archive and audit the results of the run

Creating a new training run with different data or hyperparameters is direct and simple. You can access the run from the lineage screen, and clone it right from there
By tracing back the lineage to the program or dataset, you can also see where else that code or dataset was used. This provides insight into how broadly your inputs are being selected for training. You want to ensure that you’re not using the same dataset over and over, for example, which might overfit your training to a specific dataset.
Finally, once you have a workflow established, DKube enables flexible and powerful automation through Kubeflow Pipelines or CI/CD.
DKube enables best-in-class components to be brought together for your experiments and training. And it allows data scientists to focus on the science.





